
RAG Is Easy. Your Data Isn’t.

I joined a discovery call. The brief beforehand: “This is basically a copy of Project X. Same timeline.”
Project X was a marketing chatbot. Conversational, no proprietary knowledge base. Search integration and personality. We knew that scope.
Thirty minutes into the call, it’s clear this isn’t RAG. Data processing from S3 buckets, Lambda triggers, ETL pipeline. That’s table stakes. The real work? Teaching the model to query and reason over that structured data. That’s not a chatbot. That’s a different project entirely.
“Same timeline” for a completely different architecture.
This happens constantly. Not because clients mislead us. Because the gap between “AI chatbot” in their head and “AI chatbot” in reality is massive.
The pattern is clear: most projects don’t struggle because the engineering is hard. They struggle because everyone underestimates what comes before the engineering starts.
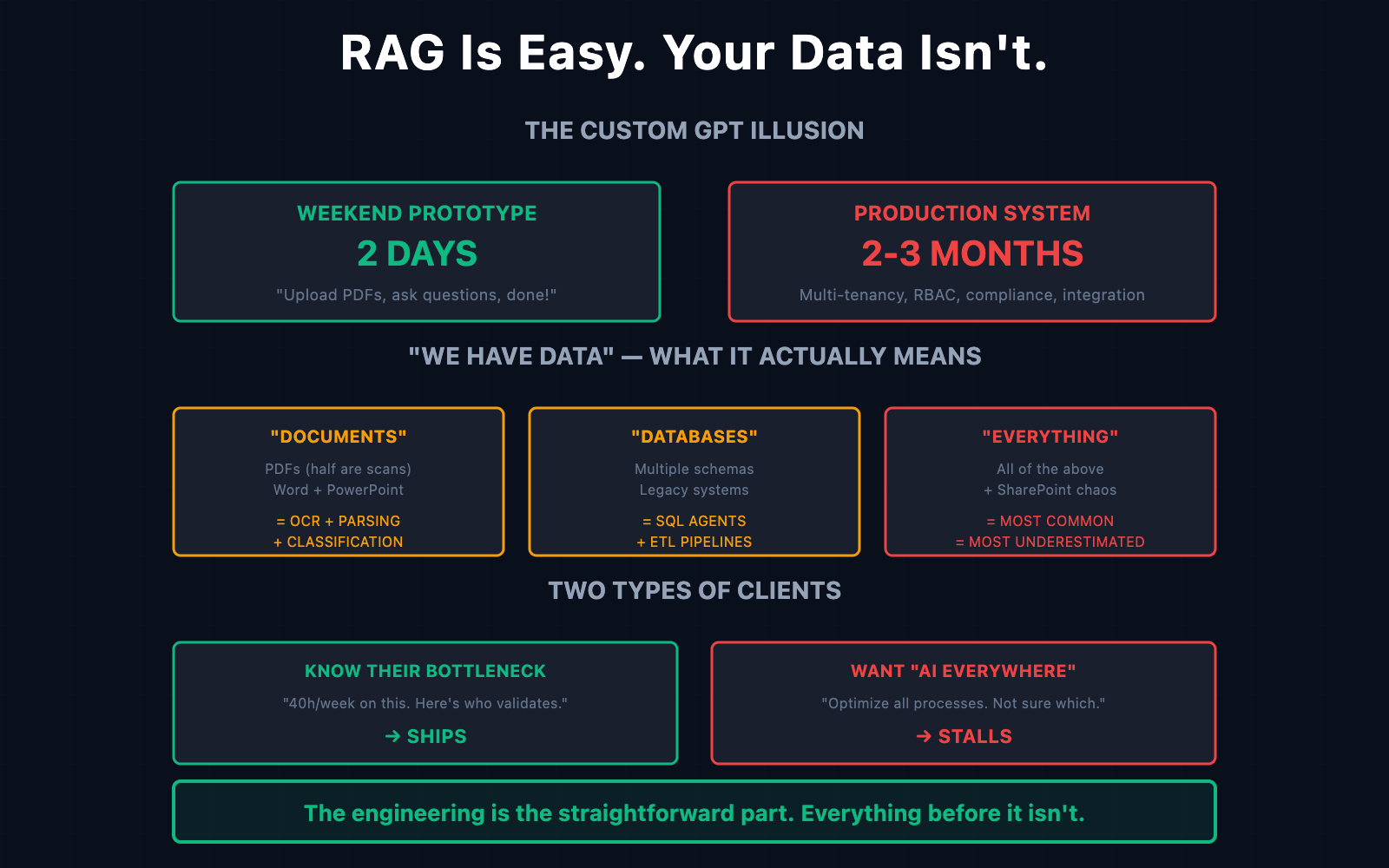
The Custom GPT Problem
Client built a Custom GPT over a weekend. Uploaded some PDFs. Asked it questions. It worked. They showed their CEO. Everyone got excited.
“We want this, but for the whole company.”
That’s where it stops being simple.
“For the whole company” means multi-tenancy. Different departments see different data. Role-based retrieval: sales can’t access HR documents, legal can’t see engineering specs. Audit logs. Access controls. Compliance.
Custom GPT doesn’t do any of that. It’s one user, one knowledge base, no permissions. The jump from “it works for me” to “it works for the organization” isn’t a small step. It’s a different architecture.
NotebookLLM, Custom GPTs. They create a dangerous illusion. They make AI feel simple because all the enterprise complexity is hidden. The prototype took a weekend. The production system takes months.
“We Have Data”: The Three Versions
Every client says they have data. They mean different things.
Version 1: “We have documents.” They have PDFs. Some are text. Some are scans. Some are text with scanned tables embedded. Some are PowerPoints where the real information lives in speaker notes nobody exports.
This isn’t a data problem you solve once. It’s a classification problem, an OCR problem, a parsing problem, and then a chunking problem. Each one adds weeks.
Version 2: “We have structured data.” They have databases. Multiple databases. With different schemas. Some legacy system from 2012 that nobody fully understands anymore. CSV exports that break because someone used commas in a text field.
Now you’re not building RAG. You’re building SQL agents, data transformation pipelines, and schema mapping. Different architecture entirely.
Version 3: “We have both.” Documents and databases and spreadsheets and emails and a SharePoint nobody’s organized in years.
This is the most common version. And the most underestimated.
The Access Tax
Data and credentials need to arrive on day one. They rarely do.
We’ve waited weeks for database access. Months for IT security approvals. One project stalled because a single stakeholder controlled API credentials and went on vacation.
Every week of waiting is a week of zero progress. But in the client’s mind, the timeline keeps running from the day they signed the contract.
The access problem isn’t technical. It’s organizational. And organizations move slowly.
Two Types of Clients
We can predict project outcomes from the first call.
Clients who know their bottleneck: “We spend 40 hours weekly on this specific process. Here are inputs and outputs. Here’s the domain expert who’ll validate results.”
These projects ship. Clear scope, measurable outcome, someone internal who can evaluate accuracy.
Clients who want AI everywhere: “We want to optimize our processes. We’re not sure which ones yet.”
These projects stall. Not because AI can’t help. Because you can’t optimize processes that aren’t documented. You can’t measure improvement without baselines. You can’t validate AI outputs without domain expertise.
The technology isn’t the constraint. Organizational readiness is.
The Work That Isn’t Ours
Here’s what successful projects require from the client side:
Domain expertise for validation. We build the system. We cannot tell you if the output is correct for your industry, your regulations, your edge cases. That’s your job.
Evaluation data. Before we write code, we need examples: “When users ask X, good answers look like Y.” Hundreds of them. This is how we measure progress versus confident wrongness.
Accuracy decisions. 85% accuracy in 6 weeks. 95% might take another 6 weeks. 99% might be impossible with your data quality. Those last 5% for 2% of users might cost 40% of the budget. You decide if it’s worth it.
Ongoing maintenance. When source documents change, someone updates them. When accuracy drifts, someone investigates. This isn’t a one-time build. It’s an ongoing operation.
Most clients expect to hand off requirements and receive a product. AI doesn’t work that way. It’s a collaboration that requires their continuous involvement.
Simple Project, Real Timeline
Best case scenario. Clean data, clear scope, engaged stakeholder with domain knowledge.
6-8 weeks. Most of that time goes to prompt engineering and iteration. Not infrastructure.
But “clean data” is rare. “Clear scope” requires work upfront. “Engaged stakeholder” means someone’s calendar is blocked for this project, not squeezed between other priorities.
When any of these are missing, multiply the timeline. When all three are missing, reconsider starting.
Why Projects Don’t Reach Production
Projects rarely fail technically. They fail organizationally.
Built but never integrated. We deliver a working system. It sits in staging because the client doesn’t have engineering resources to integrate it. They budgeted for building, not deploying.
Value mismatch discovered late. Midway through, the client realizes the problem they described isn’t their actual pain point. The AI works. The business case didn’t.
Diminishing returns rejected. We explain the math: last 5% of accuracy for edge cases costs 40% of remaining budget. They want it anyway. Then budget runs out. Then the project is “over scope.”
None of these are engineering problems.
What Actually Helps
Before signing contracts, dig into the actual data. Not descriptions of data. The data itself.
We run a Rapid Validation Sprint. Four weeks. Real data access, real complexity mapping, real unknowns identified. Then we estimate based on reality, not assumptions.
The companies who quote 50% less aren’t doing this work. They’re guessing. When the data turns out messier than expected (it always does), they either blow the budget or cut scope.
The Point
RAG tutorials make this look easy. Upload documents, chunk them, embed them, query them. Done.
Production is different. Data is messy. Access is slow. Validation requires domain expertise you don’t have. Accuracy expectations exceed what the data supports.
The engineering is the straightforward part. Everything that comes before it: that’s where projects actually succeed or fail.
Most AI initiatives struggle not because the technology isn’t ready. Because the organization isn’t ready. Data isn’t organized. Processes aren’t documented. Nobody’s assigned to validate outputs.
That’s not a criticism. It’s just the reality.
The question isn’t whether AI can help your business. It’s whether your business is ready to help the AI.
What’s been your experience with AI project expectations versus reality? Reply, I read every response.
If this resonates, forward it to someone about to sign an AI contract. Better they hear this now.
Like & Share, I appreciate your activity.
I'm living this as a learning experience now. RAG tutorial w/ some product docs, I then turned my attention to our support issue DB. 6 weeks later I have a ~functional~ MSSQL to embeddings pipeline that takes 2 days to create run a half-million chunks. While it ran, I learned how to do multi-stage asynchronous embeddings from Copilot (DB to files, files to vector tables, all decoupled). Later on, I realized I have a handful of 400K-word issues that I had to learn how to do chunked summarization on. It's been quite the 2 month period for learning, and I have to say that programming has gotten interesting again.
And then there was the Claude review yesterday wherein I learned I did the embeddings incorrectly. It was only test data, and I would have to re-embed anyway, but I'm happy Claude caught it. Copy-paste and I forgot to change a field name so that "Issue description" got embedded as the "Issue details". Ouch.