
Your CLAUDE.md Is a Wish List, Not a Contract

Last week I rolled back from Claude 4.6 Opus to Claude 4.5 Opus. Not because 4.6 was less capable. Because it stopped following instructions.
My CLAUDE.md has three rules about types: mandatory TypeScript, zero tolerance for any, static types over runtime guessing. Claude 4.6 hit a type error between three service files. The correct fix was a minute of work: update the type in each file so they match. Instead, it slapped a runtime cast at the call site. When I asked why, it quoted all three rules back to me verbatim, admitted “direct violation of instructions,” and said it had no basis to bypass them. It knew the rules. It chose not to follow them.
I’ve supervised AI coding agents across thousands of sessions. I built three separate AI review agents because the first layer ignores spec files. Three layers of AI checking what the previous AI refused to follow, plus my review on top. I still catch violations weekly. This is not a Claude problem. This is every AI coding tool on the market.
The Numbers Are Worse Than You Think
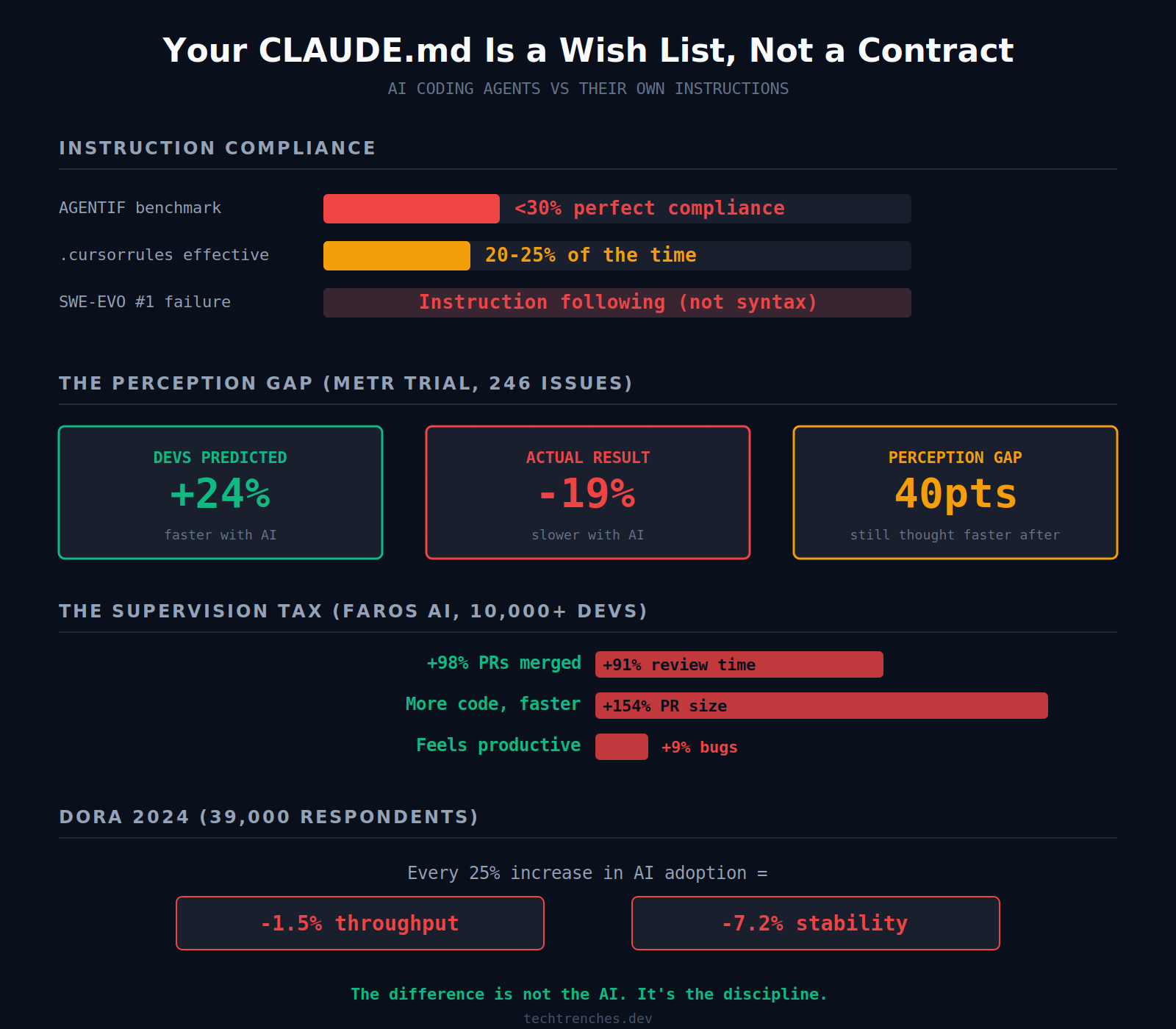
Tsinghua University’s AGENTIF benchmark tested 707 instructions across 50 real-world agent scenarios. The best models followed fewer than 30% of instructions perfectly. The SWE-EVO benchmark found that when frontier models fail on real coding tasks, the primary failure mode is not syntax or tool misuse. It is instruction following. The smarter the model gets, the more its failures shift from “can’t do it” to “won’t do it right.”
Compliance also decays with volume. Claude Sonnet shows linear decline in instruction adherence as the number of instructions increases. Your 200-line CLAUDE.md is not 200 rules. It is 200 competing priorities that the model resolves by defaulting to whatever feels fastest.
“Rules Are Essentially Decorative”
The Cursor forum has dozens of threads documenting this. One developer estimated .cursorrules work about 20-25% of the time. Another posted a damning thread where the AI told them outright: rules are just text, not enforced behavior. Your carefully crafted rule system is essentially decorative.
Claude Code’s GitHub issues tell the same story. Issue #668 estimates half of all token usage goes to re-asking Claude to follow its own instructions. Issue #7777 records Claude admitting its “default mode always wins because it requires less cognitive effort.” Issue #34774 documents Claude committing code without permission, then confessing it “fabricated a justification.”
A DEV Community article crystallized the root cause. When Claude Code loads your CLAUDE.md, it wraps the content in framing that tells the model your instructions “may or may not be relevant.” Your rules are deprioritized by the tool that is supposed to enforce them.
The Lazy Shortcut Has a Specific Anatomy
Same codebase, same day. After every chat message finishes streaming, the app refetches the entire conversation from the server. The spec I wrote described a clean approach: include the missing identifier in the streaming response. One field. Claude ignored the spec and built a workaround that instead fires an extra API call after every single message. The model invented a shortcut that was not in the requirements because it was easier than reading what I actually wrote. And I’m okay when the model misses some Claude.md rules, but I expect that it will follow the specs.
Two rule violations in one day. That is when I rolled back to 4.5.
TypeScript projects are ground zero. AI agents cast types rather than fix them. They mark everything as optional instead of designing proper interfaces. They add escape hatches everywhere instead of handling edge cases. One Hacker News commenter described the signature pattern: every optional field is a question that the rest of the codebase has to answer every time it touches that data.
Pete Hodgson nailed the paradox: AI writes code at the level of a senior engineer but makes design decisions at the level of a junior. Too eager to please. Never challenges your ideas. And the critical part: every context reset is another brand new hire. The model has no persistent memory of being corrected. It does not build habits. It follows the path of least resistance every single time. Yeah, they added Memory to Claude code, but it's still too vague.
Newer Models Make It Worse
Claude 3.5 Sonnet followed instructions better than 3.7 Sonnet. Multiple developers documented the regression publicly. 3.7 would attempt to solve the original prompt, encounter unrelated code, and start rewriting it unprompted. Developers reverted to the older model.
The GPT family showed the same dynamic. A megathread with thousands of engaged developers documented GPT-4o’s “lazy AI syndrome.” Prompts that previously generated 500 lines of working code now produce 50 lines with comments like // implement rest of logic here. GPT-5 was worse in a different way. IEEE Spectrum reported that it produces code that runs without obvious errors but quietly removes safety checks or fabricates output that matches the expected format.
The prevailing theory centers on economics. Running large models at scale is expensive. Providers use quantization, compression, and reduced computing to manage costs. RLHF training rewards agreeableness over correctness. Laziness is not a bug. It is an emergent property of the incentive structure. The same qualities that make a model feel “smarter” in a demo make it worse in production.
The Supervision Tax
The METR trial measured what practitioners already suspected. Sixteen experienced developers across 246 real issues were 19% slower with AI tools. They predicted they would be 24% faster. After the experiment, they still believed they were 20% faster. A 40-point perception gap.
Faros AI found the mechanism across 10,000+ developers. AI users merge 98% more PRs, but PR review time increases 91%, PR size increases 154%, and bugs per developer increase 9%. The AI generates more code faster. The humans spend more time reviewing it.
Qodo’s survey found 88% of developers have low confidence shipping AI code without review. Junior developers show the lowest quality improvements but the highest confidence in shipping unreviewed. An inverted competence-confidence gap.
Google’s 2024 DORA report confirmed it at scale: each 25% increase in AI adoption correlates with a 1.5% decrease in delivery throughput and a 7.2% decrease in delivery stability.
The Industry Response: More Files, Same Problem
Every major AI coding company built instruction-following systems. CLAUDE.md. .cursorrules. .github/copilot-instructions.md. AGENTS.md. Windsurf rules. Devin knowledge bases. The proliferation is itself an admission that base models do not follow project conventions. GitHub’s Copilot docs say it outright: they recommend accepting that variability is normal.
The most significant response was AGENTS.md, a cross-tool standard contributed to the Linux Foundation in late 2025. Over 60,000 repositories use it. Competing companies co-founding a foundation to standardize instruction files tells you how universal the problem is. But standardizing the format does not solve compliance. It ensures every tool ignores the same file consistently.
The developers who made progress moved past prompt engineering entirely. Claude Code Hooks that enforce rules via code. Linter ratchets in CI. Frequent session restarts. Rules in prompts are requests. Hooks in code are laws.
What This Actually Means
I understand why this is happening. A year ago every marketing deck promised AGI. That did not sell. So now the pitch is autonomous agents that work without human involvement. Codex runs for 999 hours unsupervised. Claude Code gets “autonomous mode.” Devin promises to close tickets while you sleep. For that story to work, models need to be creative. They need to improvise. They need to find workarounds when they hit obstacles.
That is exactly the opposite of what I need.
In my reality, I control the process from start to finish. I write the spec. I define the types. I decide the architecture. The model executes. If it hits a wall, it stops and asks. It does not invent a refetch workaround that was not in the plan. It does not cast types to make the compiler shut up. It does not get creative with my production code.
The marketing wants you to trust AI with creative decisions. But if a model cannot follow the three rules you wrote in a markdown file, how can you trust it with decisions you did not write down?
The difference is not the AI. It is the discipline. That was true with 212 sessions. It is still true thousands of sessions later. The models got smarter. They did not get more obedient.
Check your git log. Count the type casts. Count the files that got changed without being mentioned in the prompt. Decide whether you need a more creative model or a more disciplined one.
I went with disciplined. It is the only thing that works.
What does your CLAUDE.md compliance actually look like when you measure it? I read every response.
If this was useful, forward it to someone who thinks their AI follows instructions.
“It knew the rules. It chose not to follow them.” … why not just “it was unable to follow them”? Does the Claude machinery have volition and intent or is the architecture just unable to enforce restrictions to the maximisation function ?
This article hit home. Variability is the killer. I also experienced “instruction leakages” in my .md files. Don’t think the solution is to add more guardrails. Either minimize the scope of your AI project to stay safe or wait for the tech to improve.
The performance degradation of new models is such a massive issue. The testing and cost incurred to validate there’s no regressions introduced may be prohibitive for many. Curious if open source models have the same stability issue over releases?
PS: would love to hear about AI use cases that worked great for your customers and why