
Nobody Won the Token Race

I pay $200 a month for Claude Code. The rest of the company runs on the corporate plan at $125 a head. PMs, engineers, product, and marketing all use it. I have never once hit a usage limit. A couple of the engineers running at 5x throughput bump into it occasionally, but rarely.
We didn’t lay anyone off, and we’re hiring into every department.
We never had to fight the token bill, because we were never burning tokens for the sake of burning tokens, and the bill stayed boring because the usage stayed honest.
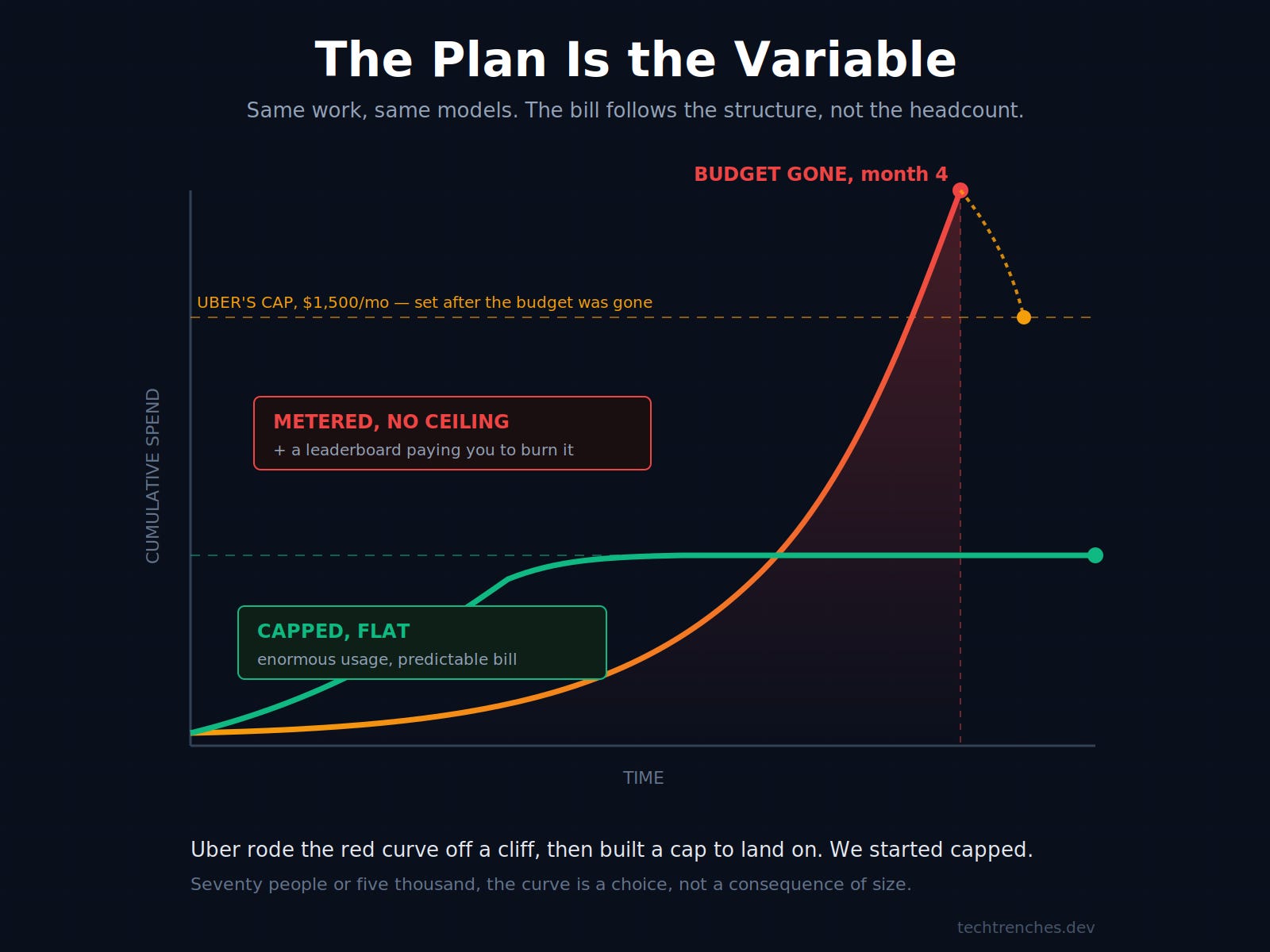
Here’s the objection I can already hear: we’re seventy people, not five thousand, so of course the bill is small. Except scale isn’t what moves a token bill. My $200 Max sub and the team’s $125 Premium seats are capped: you hit the ceiling, the window resets, the cost is known in advance. Uber put its 5,000 engineers on enterprise billing, where every token is metered on top of the seat fee with no ceiling, then ranked teams on a leaderboard by how many of those uncapped tokens they burned. That’s not two decisions, it’s one. Picking the meter with no ceiling and rewarding people for running it hard are the same managerial move: optimize activity, pay for activity. At Uber’s scale the contract is custom and metered by default, so the ceiling isn’t a checkbox, it’s something finance has to negotiate for, and they didn’t. The number of engineers was never the variable. The structure you chose and the behavior you rewarded inside it were. As of this week Uber agrees: it just capped engineers at $1,500 a month per tool, the ceiling it took a year and a blown budget to want.
What the Industry Decided to Measure
Uber wasn’t alone, and the cap came late. Over the last year a lot of companies made the same quiet decision: usage became the metric. Not output or shipped features or revenue, just consumption, a number that went on a dashboard, and numbers on dashboards become things people optimize.
Uber’s leaderboard ranked teams by how much AI tooling they used, and adoption of agentic coding jumped from 32% in February to 84% in March, until 95% of engineers were touching it monthly. The point of the board wasn’t to ship more, it was to use more, and it worked.
At Meta, an employee built a leaderboard called “Claudeonomics” that ranked around 85,000 workers by token consumption, sixty trillion tokens in thirty days, with leadership publicly cheering the token race as a productivity signal until the dashboard leaked and got pulled within two days.
Amazon built a usage leaderboard, told staff the token stats wouldn’t count toward performance reviews, and watched employees game it anyway because nobody believed them. Duolingo went further and actually tied evaluations to AI adoption, then reversed it when staff pointed out it rewarded tool usage instead of results. Different companies, same move: give people unlimited access and a culture that treats consumption as a virtue, and the bill writes itself.
The Metric Was Never Measuring Productivity
A high token count is not a signal that a lot got done, it’s a signal that AI got used without a reason. The companies that built usage metrics assumed consumption tracked productivity, when it tracks the absence of intent.
When you use AI to solve an actual problem, the usage is bounded by the problem, because there’s only so much actual work. This holds whether a human is prompting or an agent is running overnight: an agent pointed at a real task refactors what needs refactoring and stops. What doesn’t stop is an agent pointed at nothing in particular, re-running and re-checking because no one defined where done is. You don’t hit the ceiling when the work has an edge. You hit it when the work was never the point.
This is Goodhart’s law with a token meter attached. Uber’s own COO, Andrew Macdonald, put it plainly: it’s very hard to draw a line between the token spend and actual consumer improvements. That’s the tell. When you can measure the input down to the token but can’t connect it to the output, you were measuring the wrong thing.
Tokens aren’t even the first version of this mistake. Y Combinator’s Garry Tan spent the spring posting his lines-of-code totals like box scores: 37,000 LOC a day across five projects, a 72-day shipping streak, his whole Claude Code setup open-sourced so everyone could match the number. Then a developer opened the blog all that throughput produced and counted 78,400 lines of what he called AI slop in production. Lines of code, like tokens, measure how much the machine ran, not whether anything worth shipping came out.
They built systems that rewarded exactly the behavior that creates no value, then expressed surprise at the invoice.
Why Our Bill Is Boring
We use AI when it solves the task in front of us and not otherwise. That’s the entire policy. The spec-driven approach I’ve written about before forces clarity before a single token gets spent: you specify the problem, the AI works the problem, and there’s no “let’s see what it comes up with,” the prompt that quietly multiplies your bill by ten. The same instinct governs the model: I’m on 4.5 and 4.6, not the newest release. When 4.7 shipped with a tokenizer that generates up to 35% more tokens for the same input, I didn’t move, because there was no reason to. The older models do the work on fewer tokens. Chasing the newest model and gaming a usage leaderboard are the same instinct wearing two outfits: consumption mistaken for progress.
We never made using AI the point, and we use it constantly. PMs run tickets through it against our templates and acceptance criteria. QA runs bug reports through it so they’re clear enough for anyone to act on. Marketing crawls the web with it for angles. Product builds per-client RAG out of meeting notes, docs, and history. Engineering, obviously. Every department vibe-codes its own internal tooling, and then the CTO rewrites the worst of it like a human being. The usage is enormous. It just isn’t stupid. The bill stays flat not because we use AI less, but because every run has a task attached, and a task has an edge. We never tried to take the human out of the loop. The AI is a tool the person reaches for, not a replacement we’re proving out, so nobody is burning tokens to hit a number or make a headcount go away. The work still belongs to a person. The bill is just what the tool cost them.
The Uncomfortable Part
The pitch for all of this was replacement: AI would do the work and cut the cost, fewer people, smaller payroll, same output.
The trouble is the meter has no fixed relationship to a salary. A single autocomplete costs a fraction of a cent; running Claude Code as an autonomous agent across a monorepo can burn thousands in an afternoon, Uber’s own CTO spent $1,200 in a two-hour demo and later said the year’s budget was gone four months in. Average engineers at Uber ran $150 to $250 a month, heavy ones $500 to $2,000, and the leaderboard rewarded the heavy end. Put 5,000 of them on an uncapped meter that pays them to run it hot and the per-head bargain is what turns into the overrun that ended the experiment. On the heaviest agentic workloads the trade flips outright: Nvidia’s VP of applied deep learning told Axios that for his team the cost of compute is already past the cost of the employees. Then add the people the pitch forgot, the prompt engineers, the eval pipelines, the reviewers, the supervisor rebuilding everything each time a model version changes behavior. The token bill doesn’t replace payroll. It lands on top of a thinner one.
And it doesn’t do the work that actually needed a person. This isn’t one company’s bad call, it’s a pattern with numbers on it. Orgvue surveyed more than 1,100 executives, and among those who’d cut staff for AI, 55% say they regret it. A Careerminds survey of HR teams who’d run AI layoffs found most had already rehired a third to half the roles within months, and nearly a third said rehiring cost more than the automation saved. AI handled the tickets that never needed a person and broke on the ones that did.
The savings were supposed to come from replacing people, and replacing people is the one thing it can’t do, so the savings never arrived. To get there, nearly 80,000 tech jobs went in the first quarter with companies pinning the blame on AI. Among the ones that rehired, nearly a third found the rehire cost more than the cut had saved. They let go of the people who understood why the work mattered, kept a tool that can’t replace them, and called it the smart move. For what? If the goal was saving money, the layoffs aren’t a side effect of efficiency, they’re a loss booked as one.
The companies that read it right did the opposite. IKEA let its bot Billie take the 47% of queries that were routine, then looked at the other 53%, the ones that needed taste and judgment, and reskilled 8,500 call-center workers into remote design advisers instead of cutting them. The AI handled the part that was never the point. The people kept the part that was.
And the safe choice is getting harder to make. On June 1 GitHub moved every Copilot plan to usage-based billing: autocomplete stays free, but chat and the agentic modes now draw on a monthly pool of token credits, and when it runs dry you pay by the token. One Pro+ user torched 8% of the allotment in two hours doing work that used to be a fixed cost. Anthropic does the same on June 15, splitting programmatic usage onto a separate metered credit at API rates while interactive use stays flat. Both vendors are carving the agentic layer off the flat fee, so the capped plan that keeps a bill predictable is exactly the thing being phased out.
Per-token prices are climbing regardless, subsidies are ending, and the economics are tightening for everyone. None of that is the part you control. What you control is whether the spending has a task attached to it, or just a number to grow.
A well-used AI is a great intern, and intentional usage keeps the intern affordable. It doesn’t change what the intern is. Spend less and you’re left with the same tool, minus the giant bill.
If consumption is up and you can’t draw a clean line from a token to a shipped outcome, you don’t have a productivity story. You have a leaderboard.
It's the 3rd of June and at work emails are already flying around about the github copilot billing change, which has already stopped some colleagues AI-assisted work - it's affecting internal policy and requiring budgets to be set (= money suddenly needs to be found).
And to be honest our interns are still better than the AI... _and_ they have a conscience.
I think you touch on really good points here. The issue is AI has to replace humans to match the lofty valuations, investments and ultimately revenue that have been made and have been promised. The current economic equation around AI is based on this. It feels like we are at a turning point when the ‘value’ if AI is increasingly questioned against a tighter lens…feels like we are headed for a correction